1、背景
数字信号处理是现代通信、雷达和电子对抗设备的重要组成部分。在实际应用中,利用数字信号处理技术对接收数据进行处理,不仅可以实现高精准的目标定位和目标跟踪,还能够将目标识别、目标成像、精确制导、电子对抗等功能进行拓展,实现多种业务的一体化集成。
在现代雷达系统中,随着有源相控阵和数字波束形成(DBF)技术的广泛应用,接收前端存在大量的数据需要并行处理,并需要保证高性能和低延迟的特点。雷达日益复杂的应用环境,让雷达系统具备自适应于探测目标和环境的能力,数字信号处理部分也需要使用多种更加复杂的算法,并且可以做到算法模块化,以及通过软件配置功能模块的参数,实现软件定义的功能。更大的数据处理带宽能够使雷达获得更高的分辨率,更高的工作频率使得雷达可以小型化,能够在更小的平台上安装,这样对于硬件平台实现也有低功耗的要求。
在电子对抗设备中,可以在最短的时间内对多个威胁目标进行快速分析和响应,同样需要数字信号处理的相关算法具备高实时,高动态范围和自适应的特点。如何在宽频噪声的环境中寻找到目标的特征数据,如何在宽带范围内制造虚假目标实现全覆盖,数字信号的处理性能是至关重要的设计因素。
加速云的SC-OPS和SC-VPX产品,针对5G通信和雷达的数字信号处理的要求,结合Intel最新14nm工艺的Stratix10 FPGA系列,提供了一套完整的硬件和软件相结合的解决方案。SC-OPS产品作为单独的硬件加速卡,通过PCIe插卡的方式实现与主机的通信功能,还可以通过多卡级联的方式实现数字信号的分布式处理方案。SC-VPX产品是由FPGA业务单板、主控板和机箱组成的VPX系统。借助于FPGA可编程的特性,加速云提供了高性能数学加速库FBLAS和FFT的RTL级IP,具有高性能和算法参数可配置的特点实现了多重信号分类(MUSIC)和自适应数字波束形成(ADBF)的核心算法,提高了5G通信和雷达在对抗干扰方面的性能。为了方便客户使用高层语言开发,加速云提供基于FPGA完整的OpenCL异构开发环境,快速实现用户自定义的信号处理加速方案。


图1、加速云SC-OPS和SC-VPX产品
2、方案组成
2.1 基于SC-OPS产品的系统架构图

图2、SC-OPS产品系统框图
基于SC-OPS产品的系统分别由硬件资源层,算法实现层和应用层三部分组成。
SC-OPS加速卡作为主要的硬件平台,采用IntelStratix10 GX2800 FPGA器件,集成2753KLE资源和9.2TFLOPS单精度浮点计算能力。单板支持2个40/100G光口或电口,支持板间通信以及设备间级联。板卡支持8个DDR4-2400MHz 72bits位宽的内存通道(ES支持2133MHz),以及PCIeGen3 16Lane的主处理器通信接口。
通过在主机内插入一张或多张SC-OPS加速卡的形式,可以实现不同性能的硬件集成。以一机八卡服务器为例,整机具备73.6TFLOPS的单精度浮点计算能力,并具有纳秒级低延时特性,可应用于高性能的数字信号处理的解决方案。加速云在算法实现层提供了基于FPGA逻辑实现的高性能数学加速库FBLAS,FFT,MUSIC和ADBF核心算法,以上功能模块都是以IP形式提供,并提供相应的API接口函数,通过PCIe接口实现在应用层的调用,从而可以搭建软件定义雷达系统,实现超高性能高灵活的雷达仿真平台。对于更加关注于自定义算法实现的用户来说,加速云还可以支持面向OpenCL的FPGA异构平台开发环境,提供了SC-OPS板卡对应的BSP,用户只需要自行编写OpenCL Kernel和Host程序,即可以快速的实现相关算法的二次开发。
2.2 基于SC-VPX产品的系统架构图
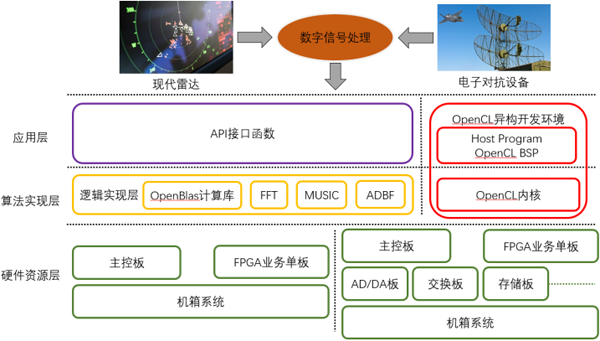
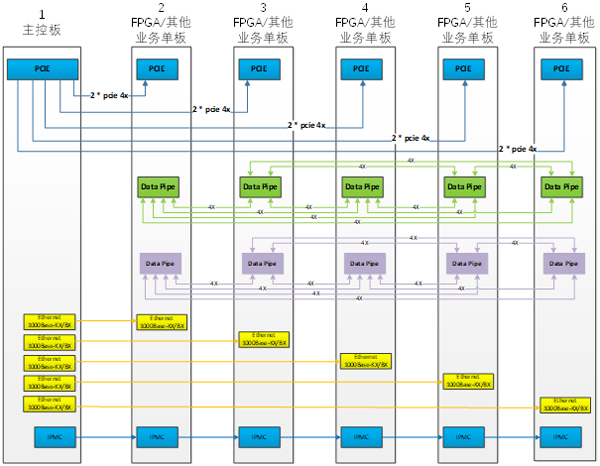
图3、SC-VPX产品系统框图
基于SC-VPX产品的系统,与SC-OPS相比,区别在于硬件平台实现。SC-VPX系统由5块FPGA业务单板,1块X86主控板和6U标准VPX机箱组成。其中FPGA业务单板采用板载XEON-DX86主控和1~2片Stratix10 GX2800 FPGA器件的方案,集成2753K*2 LE资源和9.2 *2 TFLOPS单精度浮点计算能力。每片FPGA支持4个DDR4-2400MHz 72bits位宽的内存通道。前面板支持8个17.5Gbps光口,背板提供32个10.3125Gbps的高速接口,支持业务单板之间的全mesh高速互联网络,X86主控板与业务单板之间采用PCIe和GE的双控通信方案。
用户可以选择加速云提供的主控板和多块FPGA业务单板,整机最高可以支持92TFLOPS单精度浮点处理能力,配合相关算法IP,实现多种数字信号处理的算法或者分布式实现大容量数据处理的算法。由于SC-VPX整套系统都是符合OpenVPX的标准,用户可以添加其他各种功能板卡,包括AD/DA板、RapidIO交换板、存储板等,结合加速云的主控板和FPGA业务单板,组建成一套完整的信号接收处理雷达系统,无论是应用于相关产品还是科研,都可以帮助用户实现系统级的解决方案。
3、系统优势
3.1优异的能效比
能效比是评估数字信号处理时一个关键的指标,即GFLOPS per Watt。表1中罗列了各类设备平台的数字信号处理能力的能效比,加速云采用IntelStratix10 FPGA的方案具备最优的能效比。
| 类型 | 系列 | 单精度浮点 运算能力 |
功耗 | 能效比 |
| FPGA | IntelStratix10 | 9.2TFLOPS | 120W | 76.6 GFLOPS/W |
| FPGA | IntelArria10 | 1.5TFLOPS | 30W | 50 GFLOPS/W |
| DSP | TITMS320C6678 | 160GFLOPS | 15W | 10.6 GFLOPS/W |
| GPU | NVIDIA Tesla P40 | 12T FLOPS | 250W | 48 GFLOPS/W |
| CPU | 至强12核(IntelXEONE5-2697) | 219GFLOPS | 130W | 1.68 GFLOPS/W |
表1、各平台数字信号处理能力效能比的对比
3.2 FPGA IO灵活可编程
FPGA最大的特点在于IO可编程,可以提供各种高速和低速IO的协议标准,匹配用户实现多样系统互联的要求。比如SC-OPS板卡的2个高速互联接口,分别可以配置为40GE,100GE或SRIO的标准。SC-VPX FPGA业务单板的背板提供32个10.3125Gbps的高速接口支持与背板间的全mesh网络接口,分别可以配置为10GE,40GE或SRIO的标准。
3.3高性能的算法IP
加速云基于FPGA平台上提供了数字信号处理相关算法的IP,IP的性能决定了数字信号处理系统的性能,包括动态范围,信号损耗,信噪比,延时等因素。
以信号处理中常用的FFT傅里叶变换为例,相比最新的DSP平台,加速云提供的RTL级IP,使用FPGA符合IEEE 754标准的单精度浮点数字信号处理(DSP)单元,可以实现更低的计算时间。
| FFTSize | PerformanceofComputingFFT (time, ms) using TMS320C6678 | |||
| 1 core | 2 cores | 4 cores | 8 cores | |
| 16K | 0.473 | 0.261 | 0.159 | 0.131 |
| FFT Size | Performance of Computing FFT (time, ms) using FPGA | |||
| 1 PE | 2 PEs | 4 PEs | 8 PEs | |
| 16K | 0.16 | 0.04 | 0.01 | 0.003 |
表2、DSP和FPGA平台实现FFT算法的计算时间对比
以下是加速云提供的基于FPGA实现高性能数学加速库FBLAS的相关性能。可以看出,借助FPGA天然的并行处理的优势,加速云提供的算法IP,可以帮助用户实现数字信号处理系统的快速优化,极大缩短了用户产品Time-to-Market的时间。
| 算法名称 | 参数 | 数据格式 | 处理性能 |
| 矩阵求逆 | 144*144维复数 | FP32 | 120us |
| 矩阵求逆 | 72*72维复数 | FP32 | 53.6us |
| 矩阵求逆 | 24*24维复数 | FP32 | 10.32us |
| 矩阵求逆 | 12*12维复数 | FP32 | 3.76us |
| 矩阵QR分解 | 64*64维复数 | FP32 | 46.41us |
| 矩阵QR分解 | 16*16维复数 | FP32 | 4.99us |
| 矩阵QR分解 | 8*8维复数 | FP32 | 2.5us |
| 特征值分解(基于QR分解,16次迭代) | 64*64维复数 | FP32 | 5200us |
| 特征值分解(基于QR分解,16次迭代) | 16*16维复数 | FP32 | 150us |
| 特征值分解(基于QR分解,16次迭代) | 8*8维复数 | FP32 | 65us |
| 协方差矩阵(快拍数K=256,通道数N=8) | 8维复向量 | FP32 | 30us |
| 协方差矩阵(快拍数K=256,通道数N=16) | 16维复向量 | FP32 | 60us |
| 协方差矩阵(快拍数K=256,通道数N=64) | 64维复向量 | FP32 | 128us |
| 线性方程求解 | 200维 | FP64 | 420us |
表3、FPGA实现高性能数学加速库FBLAS性能示例
3.4完整的OpenCL异构开发环境
加速云SC-OPS和SC-VPX产品都可以支持面向OpenCL的FPGA异构平台开发环境,提供全面的数学库支持,解决了传统FPGA遇到的时序收敛、DDR存储器管理以及PCIe主处理器接口等难题。另外加速云也支持将高性能算法IP作为定制化组件,与OpenCLKernel集成在一起,提供灵活的算法配置解决方案。
4、应用案例
4.1多重信号分类(MUSIC)
MUSIC算法是经典的空间谱估计算法,实现波达方向估计(DOA)的相关应用。在电子侦察和电子对抗等对实时性要求严格的领域中,如何选用合适的平台实现并满足系统的响应处理速度,成为了设计者颇为头疼的问题。整个MUSIC算法计算复杂度和灵活度都很大,而且电子对抗系统都有浮点处理的要求,所以大多用户会采用DSP处理器的方案,处理时间停留在ms量级。加速云采用Intel集成全新浮点计算单元的FPGA,全硬件实现了基于MUSIC算法的空间谱估计DOA全部算法(MUSIC算法是基于加速云高性能数学加速库FBLAS搭建的,所有组成IP都可以单独调用)。相比DSP处理器,极大提升了MUSIC算法的实时性,超过10倍以上的性能改进。
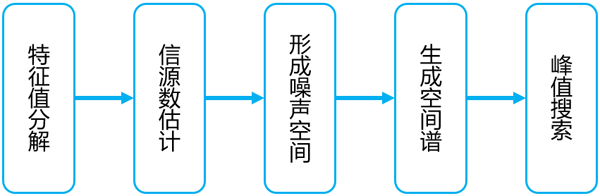
图4、FPGA实现MUSIC算法的处理流程
MUSIC算法实现的相关性能如下:
· 特征值和特征向量的数值相对Matlab中EIG函数计算结果的偏差均小于10-5· 算法实现以单精度浮点为主,结合部分双精度浮点
· 全部处理时间<120us(TI6678的处理时间是ms级)
4.2自适应数字波束形成(ADBF)
随着有源相控阵雷达的广泛应用,如何有效增强期望信号和抑制无用信号,也是设计者需要考虑的问题。ADBF技术利用天线阵元的采样数据,自适应更新信号的权值,使阵列天线形成特定的期望形状。由于天线阵元通道数量大,需要实现海量数据的计算,相关平台实现必须具有高集成度、高数据吞吐率和高数据并行计算的特点。
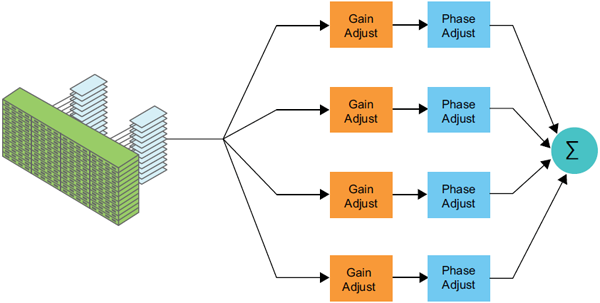
图5、DBF原理示意图
加速云借助高性能数学加速库FBLAS,通过高维数的矩阵求逆的算法,完全在FPGA内实现了ADBF的算法。
ADBF算法实现的相关性能如下:

方位维天线方向图 俯仰维天线方向图
| 算法名称 | 数据格式 | 性能指标(单拍) | 性能指标(连续) | 功耗 |
| 方位维运算 | FP32 | 455us | 245us | 30W |
| 俯仰维运算 | FP32 | 335us | 148us | 30W |
5、结论
通过参与了国内众多实际雷达数字信号处理相关产品或是科研的研发和技术合作,加速云累计了大量的经验,在此基础上推出的SC-OPS和SC-VPX产品及高性能数学加速库FBLAS、多重信号分类(MUSIC)、自适应数字波束形成(ADBF)等IP库,可以帮助用户实现系统级的解决方案。通过持续推出高密度高性能硬件平台,高性能RTL级加速IP,配合高性能分布式软件搭建高性能、低延时灵活配置的软件定义平台,推动了雷达和电子对抗设备向更先进设备的演变。
 粤公网安备 44030902003195号
粤公网安备 44030902003195号