示波器从诞生之处至今已经历了第一代模拟实时示波器ART,以数字化处理和存储功能为主要特征的第二代,以及以DPO快刷新为主要宣传点的第三代,如今已进步到第四代数字示波器,而拉开这一时代大幕的即是力科公司2008年推出的Wave Pro 7Zi和2009年推出的Wave Master 8Zi系列示波器,无论是从带宽、采样率、可分析存储、仪器响应和波形处理速度、异常问题调试、还是串行数据信号质量分析方面,都比前三代示波器有了长足的进步。
1.基础性能指标
评价一台示波器性能的几个基础指标包括带宽、采样率、存储深度、触发能力和波形处理性能。
(1)示波器的带宽定义为前端放大器的频响曲线下降3dB处的频点,就是示波器的-3dB带宽,简称带宽。所以一台6GHz带宽的示波器测量6GHz的正弦波,幅度一定会降低3dB(约降低30%)。如果你测试的对象是PCI Express G2速率为5Gbps,那对示波器带宽的最低要求为12.5GHz,通常的法则是最低带宽为串行数据率的2.5倍,目的是确保采集到5次谐波分量。而对单次阶跃脉冲而言,由于其没有频率或数据率的概念,所以必须从另外角度考量示波器带宽,那就是上升时间。如果我们以T(scope)代表示波器的10%~90%上升时间,以T(signal)代表所测量脉冲信号的上升时间,那么两者之间的比例即T(scope)/ T(signal)与脉冲信号测量精度将基本满足下表所列内容。
| T(scope)/ T(signal) | 脉冲测量精度 |
| <0.1 | 优于0.5% |
| 1/3 | 5% |
| 1/2 | 12% |
| 1 | 40% |
| >1 | 不应使用 |
从表中可以看出,为了使脉冲测量精度达到5%以上,应使示波器的上升时间小于脉冲上升时间的1/3以上。例如对上升时间在100ps以内的脉冲信号进行测量,示波器的上升时间应控制在30ps以内。我们知道示波器的带宽越高其对应的上升时间越短,对高带宽实时数字示波器而言,两者的乘积在0.35~0.51之间变动。30ps以内的上升时间将要求示波器带宽达到16GHz以上。如果对上升时间50ps以内的脉冲信号测量,则要求示波器的10%~90%上升时间必须控制在17ps以内,对应示波器的带宽将达到25GHz或者更高。力科第四代Zi系列数字示波器将带宽提高到了30GHz,使得万兆以太网或上升沿小于50ps的超快速脉冲在实时示波器上成为现实。
(2)AD采样时数字示波器里非常关键的部分,足够的采样率也是保证示波器信号保真度的关键因素之一。
数字示波器的基本原理是模拟信号低通滤波后被等时间间隔采样,然后数字化后由数字处理单元重构,最后以波形的形式在屏幕上显示。采样率越高,两次采样之间的时间间隔就越短,重构后的波形与真实信号的拟合程度就越高。一般情况下,应该保证在信号上升沿上至少采集4个样点才能比较客观的恢复出脉冲信号的真是波形并加以测量。例如,对上升时间100ps的脉冲信号,我们应该至少使用40GS/s的采样率对信号进行采集;而对于上升时间50ps以内的脉冲信号,则至少要求示波器的实时采样率达到80GS/s。力科第四代Zi系列数字示波器就能提供80GS/s实时采样率,是上升时间50ps以内脉冲测量的最好选择。力科第四代Zi系列数字示波器另一大突破是力科研制成功的单ADC芯片采样率40GS/s,避免了采用多颗低采样率芯片叠加采样的示波器架构不可避免引入的冲击电平噪声与误差,在最高80GS/s采样时仅通过两颗芯片协同工作即可完成。这样的示波器架构大大简化了从前端放大器到ADC采样芯片之间的信号通路,很好的保证了高采样时的信号一致性。值得一提的是40GS/s ADC芯片代表了全球最高的芯片设计水平,其指标记录至今无人能破。
(3)存储深度,也叫记录长度,表示示波器能连续采集到的最大波形点数。过去厂商和用户都很看重可采集存储深度,即示波器一次采集能捕获到最大点数。今天随着信号的日益复杂,需要处理的任务越来越庞杂,第四代示波器引入一个全新的概念:可分析存储深度。不仅看一次采集到的点数,还同时看复杂分析一次最多能运算的波形点数。
第三代示波器的可分析存储深度通常都比可采集存储深度小很多,主要是因为示波器处理速度跟不上,为防止系统崩溃而限制用户分析波形时的存储深度。譬如,有些示波器明明能采集到200M采样点,但FFT运算却限制最多到3.2M,用户的投资得不到充分利用。
力科在第四代采用了突破性的波形处理架构Xstream II做到了业界最高的512Mpts可分析存储深度,保证用户购买了多少物理内存,波形采集和分析就能同时用到了多少内存,从而最大限度的保护用户的投资。
2、Xstream II架构
随着电子信号的日益复杂,今天的示波器已被要求能以复杂的方法处理很长内存的波形,目的是深入信号内部洞察系统和电路行为,与这种能力有关的概念是示波器的响应和速度,工程师可不愿等待很长时间才能看到结果,他们希望使用示波器的感觉是舒适和充满信心。
与处理速度有关的因素可分为三类:
- 处理和波形读出硬件的性能
- 操作系统
- 软件处理数据的算法
当前的高端示波器处理平台主要为PC,硬件性能主要由CPU、主内存和内部总线决定。
操作系统同样很重要因为它决定了多内核、多线程模式和可寻址最大内存。力科为Wave Pro 7Zi和Wave Master 8Zi示波器配备了最强大的硬件和操作系统:CPU采用Intel Core 2 Quad(四核),每个内核的工作频率为2.5GHz。这是一种64位处理器,拥有6Mb的二级高速缓存及工作频率为1.33GHz的前端总线;容量最高达8Mb的DDR II主存储器,从采集存储器到主存储器的传送采用直接存储器访问(DMA)技术,使用4路PCIe串行通道。这些通道以高达800Mpt/s的速率把波形数据传送传送到主存储器中,而不需处理器干预。由于采用了Microsoft Vista 64位操作系统,示波器软件可以寻址到4Gb大小存储器,而32位操作系统只可以寻址最高4Gb的存储器。
但是对深存储波形处理速度起决定性作用的并非硬件和操作系统,乃是软件算法。力科公司投入巨资研发的专利技术Xstream II就是一种革命性的波形处理优化技术,正是采用该技术,才使得第四代示波器在波形处理性能方面远胜于前三代。
Xstream 处理行为可以简单概括为:长波形被分成许多的较小的波形片段。这些较小的波形片段以优化高速缓存利用率的方式进行处理。最后,最小的波形结果重组成最终的长波形结果。这一切听起来非常简单,但在实践中实现起来非常复杂。力科在这种技术中拥有多项专利。正因如此,力科示波器的性能传统上优于竞争对手的仪器,其处理速度要高出许多倍。力科最早在2002年Wave Master8000中引入Xstream结构,之后几年持续进行多项结构改进,在Wave Pro 7Zi引入的Xstream II中达到顶峰。
Xstream II的关键构成要素包括:
- 动态放置缓冲器,改善流式结构不擅长的情况;
- 预览模式,可以在缩放和示波器调整过程中快速初步查看波形结果;
- 中断处理能力,可以在示波器调整过程中暂停当前处理。
动态放置缓冲器需要把缓冲器放在处理流的合适位置(见下图),以改善处理吞吐量。
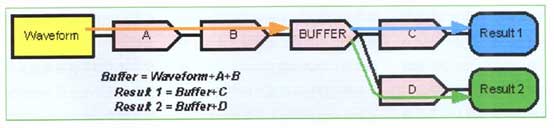
基于动态缓冲器的处理流
为了解这种影响,请记住传统处理模式在流程的每一步都涉及缓冲器。它可以视为把缓冲器放在每一个处理单元之间。传统示波器采用的流式模式中,在任何地方都使用落在高速缓存中的小型缓冲器,而包含全部处理结果的缓冲器则放在处理流最后。在Xstream II中,在多条处理流流经公共处理单元时将执行优化(如下图所示),这种结构的好处是把缓冲器动态放到处理流中,避免多次进行计算。

Xstream II采用的动态缓存预置与传统简单流式处理算法对比
Xstream II对仪器响应能力的优化主要体现在预览处理和中断处理能力(Preview and Abort)。这两者结合运行的方式是,在示波器设置发生变化时,软件开始计算新结果,同时根据屏幕画面的重新标度来计算一个预览结果。如果预览在在正是处理之前完成,那么用户先会看到预览,然后在最终完成时看到更新的处理结果。如果正式处理先完成,那么用户会只看到处理结果。如果在处理计算过程中,用户修改设置,那么将中断处理,使用新的变化重启,用户只看到预览结果。在用户设置示波器或根据测量观察结果快速改变设置时,这种处理方法非常必要。在处理过程非常复杂耗时以及波形很长时,这种功能非常实用。如果使用其它示波器中提供的传统处理方法,那么用户必须待到处理结束后,才能看到显示结果,进行另一个设置变动。在某些情况下,处理可能需要10秒以上的时间,如果用户想改变多项设置,那么必须等每个很长处理间隔的结果之后,才能进行另一项设置变动。这种操作可能会让用户很不舒服,因为每步操作都需要等很长时间才能看到结果或进行下一步动作。
总之,深存储下示波器的快速处理是适当的硬件和操作系统与适当的处理算法的结合。Xstream II是一种创新的波形处理优化技术,通过对高速缓存动态高效的处理方法,以及增加了结果预览和处理中断功能,实现了目前业界最杰出的仪器反应和波形处理能力。在实际应用中,Xstream II技术带来的性能提升程度可用下列数据来印证。
- Wave Pro 7Zi做100Mpts眼图测量时的刷新时间是20秒,而同级别的其它示波器做20Mpts眼图需要10分钟以上才能刷新一次,10Mpts眼图至少需要6分钟,100Mpts眼图刷新速度则无法测量,因为该示波器不允许用户对这么大的数据量做任何高级分析运算;
- Wave Pro 7Zi做FFT运算速度是3.8Mpts/秒,最多一次可分析128Mpts信号的频谱,而DPO示波器最快的FFT运算速度是500Kpts,为了防止大数据量造成的系统崩溃或死机,这种示波器最多允许用户运算3.2Mpts FFT;
- TriggerScan
数字示波器的一个重要应用是作为一种调试问题的工具,因此,快速查找异常事件的能力是评价示波器性能的重要标准。
电路调试通常有两个目的:第一,找出可疑问题存在的证据;第二,找出可疑问题的更多信息使得能设定触发隔离出异常信号。通过重复的触发异常信号,在不同的电路测试点观察异常事件的行为从而甄别出原因和结果之间相互关系。
定位异常信号的传统方法是触发信号的边沿,用模拟余辉方式观察叠加显示的波形,等待一段时间后期望能从累计的波形中观察到异常信号。采取这种方法时异常事件的捕获率与波形的边沿出现频率、示波器的刷新率和异常事件发生的统计概率等相关。具体表现为如果波形的边沿出现频率不超过示波器的刷新率,则示波器能捕捉到每个边沿,因此也就能捕获到每个异常事件,反之则不能捕获到每个边沿。每秒捕获到异常事件次数等于异常事件发生的概率除以边沿频率再除以示波器的刷新率。进一步可以指出,边沿出现频率小于示波器的刷新率时没什么问题,而一旦边沿出现频率超过示波器的刷新率时,捕获的概率也就对应下降。这就是为什么一些示波器厂商会创造出非常快的波形刷新模式的原因,譬如DPO。
我们可以举例进一步说明这个问题,假设有一个200MHz的时钟信号每5秒会出现一次毛刺,即异常出现的概率为10亿分之一,利用上述公式,用一台每秒能刷新10万次的示波器工作在快刷新模式,需要2.8小时,这意味着每5秒出现一次的异常信号,,示波器需等待2.8小时后才能捕获到它!效率之低,可见一斑。这里的问题是,传统的捕获异常信号的方法直接和刷新率成正比,但最快的刷新模式也还远远不够!或者说,它们并没有快到能解决实际问题的地步。工程师们真正需要的是一种比刷新率更快的方法。
用边沿触发的方法查找异常信号的问题的根本原因是每次示波器通过触发边沿来捕获波形,相邻两次捕获时,有一段示波器看不到的波形被称为死区时间。很多工程师都很惊异这个死区时间相对于示波器捕获到的时间是如此的长!在上面的例子中,示波器需要将近3小时才能看到5秒钟出现一次的异常信号,是因为示波器只能看到边沿出现的0.2%,在快刷新模式下也有99.8%的死区时间,在波形的每500个边沿中,示波器只能看到一个!
我们用一种智能触发系统来解决这个问题。当设定为触发某个特定的智能触发,它将查看波形的每个边沿直到触发成功。仅仅在智能触发条件满足,示波器触发到信号的时候才有死区时间。如果设定一种智能触发方式隔离上例中的毛刺,示波器将侦测每个边沿直到毛刺持续,以保证异常被无一遗漏被捕获。这种方法看上去简单,但在设定触发方式上有很大问题:你需要事先知道异常信号的特点,这通常是不现实的。
力科在第四代示波器中开发了一种全新的异常调试工具 TriggerScan,通过智能化使用触发系统从而解决了上述难题。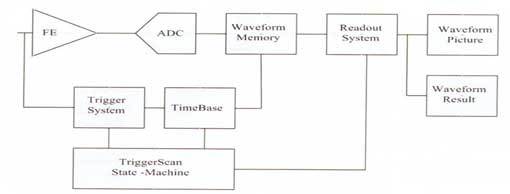
TriggerScan原理图
TriggerScan的工作过程分为两个阶段。第一个阶段操作者获取正常的波形并训练。在训练过程中,示波器首先分析波形,判断波形正常情况下的特点,然后它给出一系列的智能触发设定,这些设定都被设计为触发异常信号。例如,如果是时钟信号,那么在观察范围内,所有的边沿都有上升时间、周期和幅度,TriggerScan将设定出智能触发方式来触发超过正常范围的斜率、周期和幅度。一旦这些智能触发被设定,示波器进入工作的第二阶段,即将这些触发设定载入,每次按设定的某种触发方式工作一段时间,然后继续下次触发动作。在任何设定下一旦捕获到异常信号,获得到的波形将以余辉或停住采集的方式加以显示。
TriggerScan的有效性并非取决于边沿的频率。乃是与设定和使用的智能触发的个数有关。如果设定了100中触发方式,TriggerScan的有效性是相对于用某种特定的智能触发方式的效率的1%。TriggerScan减小了触发系统的有效性,但它能自动产生触发设置并使捕获异常信号的过程自动化。在前面的例子中,采用100000次刷新率的快刷新传统模式,平均需要2.8小时才能找到一次异常信号。采用智能触发系统,每5秒钟可以看到每个异常信号。采用具有100个触发设定的TriggerScan方法可以在平均8.3分钟内发现一次异常信号。在这个例子中,TriggerScan方法比快刷新方法要快20倍。是否具备TriggerScan智能硬件触发功能是第四代示波器的界定标准之一。
 粤公网安备 44030902003195号
粤公网安备 44030902003195号