еҹәдәҺOpenMPзҡ„з”өзЈҒеңәFDTDеӨҡж ёе№¶иЎҢзЁӢеәҸи®ҫи®Ў
0гҖҒеј•иЁҖ
йҡҸзқҖеӨҡж ёжҠҖжңҜзҡ„дёҚж–ӯеҸ‘еұ•пјҢ并иЎҢж–№жі•е·Із»ҸжҲҗдёәдёҖз§ҚеӨ„зҗҶиҫғеӨ§и§„жЁЎй—®йўҳзҡ„жүӢж®өпјҢеҗҢж—¶еңЁи®ёеӨҡйўҶеҹҹеҸ–еҫ—дәҶжҲҗеҠҹең°еә”з”ЁгҖӮзӣ®еүҚпјҢ并иЎҢз®—жі•зҡ„е®һзҺ°дё»иҰҒеҹәдәҺдёӨз§Қж ҮеҮҶпјҡ
MPI(Message Passing Interface)жҳҜдёҖз§ҚеҹәдәҺж¶ҲжҒҜдј йҖ’并иЎҢзј–зЁӢжЁЎеһӢзҡ„е·Ҙдёҡж ҮеҮҶпјҢдё»иҰҒз”ЁдәҺеҲҶеёғеӯҳеӮЁдҪ“зі»з»“жһ„зҡ„зҺ°е®һпјҢжҳҜе·Іиў«иҜҒе®һдәҶзҡ„зҗҶжғізҡ„зЁӢеәҸи®ҫи®ЎжЁЎеһӢ;OpenMPж ҮеҮҶпјҢдё»иҰҒз”ЁдәҺе…ұдә«еӯҳеӮЁдҪ“зі»з»“жһ„зҡ„并иЎҢзј–зЁӢпјҢеҸҜе®һзҺ°еңЁSMP йӣҶзҫӨзі»з»ҹеҶ…еӨҡеӨ„зҗҶеҷЁзҡ„еӨҡзәҝзЁӢ并иЎҢи®Ўз®—гҖӮ
OpenMPжҳҜдёҖдёӘеә”з”ЁзЁӢеәҸжҺҘеҸЈпјҢйҖҡиҝҮ规иҢғдёҖзі»еҲ—зҡ„зј–зЁӢеҲ¶еҜјгҖҒиҝҗиЎҢеә“еҮҪж•°е’ҢзҺҜеўғеҸҳйҮҸжқҘиҜҙжҳҺе…ұдә«еӯҳеӮЁдҪ“зі»з»“жһ„зҡ„并иЎҢжңәеҲ¶пјҢйҖҡеёёз”ұдәҺе…¶иҫғдҪҺзҡ„ејҖй”Җе’ҢзӣёеҜ№иҫғз®ҖеҚ•зҡ„зј–зЁӢиҖҢеҸ—еҲ°дәә们е№ҝжіӣзҡ„е…іжіЁгҖӮ
ж—¶еҹҹжңүйҷҗе·®еҲҶ(FDTD)ж–№жі•жҳҜжЁЎжӢҹи®Ўз®—з”өзЈҒеңәзҡ„дёҖз§Қеҹәжң¬з®—жі•гҖӮиҮӘ1966е№ҙYeeйҰ–ж¬ЎжҸҗеҮәд»ҘжқҘпјҢз»ҸиҝҮеҚҠдёӘеӨҡдё–зәӘзҡ„еҸ‘еұ•пјҢиҝҷдёҖж–№жі•еҫ—еҲ°иҝ…йҖҹеҸ‘еұ•е’Ңе№ҝжіӣеә”з”ЁгҖӮдҪҶжҳҜж—¶еҹҹжңүйҷҗе·®еҲҶз®—жі•йҖҡеёёз”ұдәҺе…¶дёІиЎҢж–№ејҸдҪҝй—®йўҳжң¬иә«еӨҚжқӮеҢ–дё”иҝҗз®—иҫғиҙ№ж—¶й—ҙиҖҢйҮҮ用并иЎҢж–№ејҸи®Ўз®—гҖӮеӣ жӯӨпјҢеңЁPCжңәдёҠз ”з©¶е№¶иЎҢFDTDз®—жі•й—®йўҳпјҢе…·жңүйҮҚиҰҒзҡ„зҗҶи®әдёҺзҺ°е®һж„Ҹд№үпјҢеҸҜдёәеӨ§и§„жЁЎе·ҘзЁӢй—®йўҳзҡ„并иЎҢеҢ–еӨ„зҗҶжҸҗдҫӣдёҖе®ҡзҡ„ж–№жі•еҖҹйүҙдёҺзҗҶи®әдҫқжҚ®гҖӮжң¬ж–Үд»ҘдёҖз»ҙе№ійқўжіўеңЁиҮӘз”ұз©әй—ҙдёӯзҡ„дј ж’ӯдёәдҫӢпјҢи®Ёи®әдәҶйҮҮз”ЁOpenMP жҠҖжңҜеҜ№з”өзЈҒеңәFDTDз®—жі•зЁӢеәҸе®һзҺ°е№¶иЎҢеҢ–зҡ„ж–№жі•пјҢ并е°ҶиҜҘ并иЎҢж–№жі•еңЁдёүз»ҙзһ¬жҖҒеңәз”өеҒ¶жһҒеӯҗиҫҗе°„FDTDзЁӢеәҸдёӯиҝӣиЎҢдәҶйӘҢиҜҒпјҢд№ҹзӣёеҪ“дәҺеҜ№иҜҘ并иЎҢж–№жі•иҝӣиЎҢдәҶдёҖе®ҡзҡ„жҺЁе№ҝпјҢ并йҖҡиҝҮе®һйӘҢиҜҒжҳҺдәҶиҜҘ并иЎҢи®Ўз®—зҡ„жңүж•ҲжҖ§гҖӮ
1гҖҒз”өзЈҒеңәзҗҶи®әз®Җд»Ӣ
FDTDж–№жі•з”ұеҫ®еҲҶеҪўејҸзҡ„йәҰе…Ӣж–ҜйҹҰ(Maxwell)ж—ӢеәҰж–№зЁӢеҮәеҸ‘иҝӣиЎҢзҰ»ж•ЈиҖҢеҫ—еҲ°зҡ„дёҖз»„ж—¶еҹҹжҺЁиҝӣе…¬ејҸгҖӮдёҖз»ҙжғ…еҶөдёӢпјҢи®ҫTEMжіўжІҝz иҪҙж–№еҗ‘дј ж’ӯпјҢд»ӢиҙЁеҸӮж•°е’ҢеңәйҮҸеқҮдёҺx,y ж— е…іпјҢеҚі- /-x = 0, -/ -y = 0 ,дәҺжҳҜMaxwellж–№зЁӢдёәпјҡ
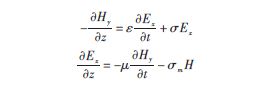
дёҖз»ҙжғ…еҶөEоҒҢ гҖҒHоҒҢ еҲҶйҮҸз©әй—ҙиҠӮзӮ№еҸ–ж ·еҰӮеӣҫ1жүҖзӨәгҖӮ

еңЁиҮӘз”ұз©әй—ҙдёӯпјҢσ = σm = 0 ,д»ӢиҙЁдёәж— иҖ—пјҢж•…иҖҢеҸҜеҫ—еңәзҡ„FDTDиҝӯд»Јж–№зЁӢдёәпјҡ
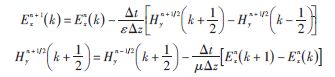
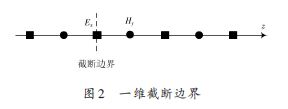
дёәдәҶж»Ўи¶іж•°еҖји®Ўз®—зҡ„CourantзЁіе®ҡжҖ§жқЎд»¶пјҢйҖҡеёёйҖүеҸ–ж—¶й—ҙжӯҘй•ҝдёә Δt з©әй—ҙй—ҙйҡ”дёә δ ,FDTDжҲӘж–ӯиҫ№з•ҢжқЎд»¶йҮҮз”ЁдёҖйҳ¶иҝ‘дјјMur,и®ҫжҲӘж–ӯиҫ№з•ҢеӨ„дёәEx иҠӮзӮ№пјҢеҰӮеӣҫ2жүҖзӨәпјҢеҲҷеңЁEx иҠӮзӮ№еӨ„зҰ»ж•ЈпјҢеҫ—пјҡ
![]()
ејҸдёӯпјҡ Ex (k - 1)дёәжҲӘж–ӯиҫ№з•ҢеҶ…зҡ„иҠӮзӮ№;c еңЁзңҹз©әдёӯдёәе…үйҖҹc0,еңЁд»ӢиҙЁдёӯеҲҷдёәжҲӘж–ӯиҫ№з•ҢеӨ„жіўзҡ„дј ж’ӯйҖҹеәҰгҖӮ
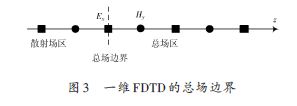
жҝҖеҠұжәҗйҮҮз”Ёй«ҳж–Ҝи„үеҶІжәҗпјҢе…¶иЎЁиҫҫејҸдёәEi (t)пјҢе…¶дёӯτ дёәеёёж•°пјҢеҶіе®ҡдәҶй«ҳж–Ҝи„үеҶІзҡ„е®ҪеәҰгҖӮдёәдәҶдҪҝе…Ҙе°„жіўйҷҗеҲ¶еңЁз©әй—ҙжңүйҷҗеҢәеҹҹпјҢж №жҚ®зӯүж•ҲеҺҹзҗҶпјҢеңЁеҢәеҹҹеҲҶз•ҢйқўдёҠи®ҫзҪ®зӯүж•Ҳйқўз”өзЈҒжөҒпјҢ并и®ҫеҲҶз•ҢйқўеӨ–зҡ„еңәдёәйӣ¶гҖӮжүҖд»ҘпјҢеңЁжҖ»еңә-ж•Је°„еңәеҢәзҡ„еҲҶз•ҢйқўдёҠ(жҖ»еңәиҫ№з•Ң)и®ҫзҪ®е…Ҙе°„жіўз”өзЈҒеңәзҡ„еҲҮеҗ‘еҲҶйҮҸдҫҝеҸҜе°Ҷе…Ҙе°„жіўеҸӘеј•е…ҘеҲ°жҖ»еңәеҢәгҖӮжң¬е®һйӘҢйҖҡиҝҮеңЁдёҖз»ҙFDTD зҡ„жҖ»еңәиҫ№з•ҢеӨ„еј•е…Ҙй«ҳж–Ҝи„үеҶІжіўпјҢеҰӮеӣҫ3жүҖзӨәгҖӮ
2гҖҒOpenMP 并иЎҢи®ҫи®Ў
2.1 OpenMPжҰӮиҝ°
OpenMPжҳҜеҹәдәҺе…ұдә«еӯҳеӮЁдҪ“зі»з»“жһ„зҡ„е·Ҙдёҡж ҮеҮҶпјҢе®ғдёҚжҳҜдёҖй—ЁзӢ¬з«Ӣзҡ„иҜӯиЁҖпјҢиҖҢжҳҜеҜ№еҹәжң¬иҜӯиЁҖзҡ„жү©еұ•пјҢеҰӮC/C++,FortranиҜӯиЁҖгҖӮе…¶зј–зЁӢз®ҖеҚ•пјҢејҖй”Җе°ҸпјҢ规иҢғ并еҲ¶е®ҡдәҶдёҖзі»еҲ—зҡ„зј–иҜ‘жҢҮеҜјиҜӯеҸҘгҖҒиҝҗиЎҢеә“еҮҪж•°е’ҢзҺҜеўғеҸҳйҮҸгҖӮеҜ№дәҺдј з»ҹзҡ„дёІиЎҢд»Јз ҒпјҢйҮҮз”ЁOpenMPжҠҖжңҜ并иЎҢеҢ–ж—¶ж— йңҖеҜ№еҺҹзЁӢеәҸдҪңеӨ§зҡ„ж”№еҠЁпјҢеҸӘйңҖеҠ е…ҘдёҖдәӣз®ҖеҚ•зҡ„зј–иҜ‘жҢҮеҜјиҜӯеҸҘеҚіеҸҜгҖӮеҗҢж—¶пјҢOpenMP жҸҗдҫӣдәҶдёӨз§ҚзІ’еәҰзҡ„并иЎҢж–№ејҸпјҡзІ—зІ’еәҰ并иЎҢе’Ңз»ҶзІ’еәҰ并иЎҢгҖӮOpenMPзҡ„з»ҶзІ’еәҰ并иЎҢжҳҜжҢҮеҲ©з”ЁOpenMP еҸӘжұӮи§ЈеҫӘзҺҜйғЁеҲҶи®Ўз®—пјҢеҸҲз§°дёәеҫӘзҺҜзә§е№¶иЎҢгҖӮз”ұжӯӨеҸҜи§ҒпјҢз»ҶзІ’еәҰ并иЎҢжҳҜдёҖз§ҚжңҖдёәз®ҖеҚ•зҡ„并иЎҢж–№жі•гҖӮ
2.2 OpenMP并иЎҢзј–зЁӢжЁЎеһӢ
OpenMPйҮҮз”Ёж ҮеҮҶзҡ„并иЎҢжЁЎејҸ--Fork/JoinејҸ并иЎҢжү§иЎҢжЁЎејҸпјҢеҰӮеӣҫ4жүҖзӨәпјҢеңЁзј–иҜ‘иҝҮзЁӢдёӯдҪҝз”Ёзј–иҜ‘жҢҮеҜјиҜӯеҸҘе®һзҺ°е№¶иЎҢеҢ–гҖӮеңЁзЁӢеәҸејҖе§Ӣжү§иЎҢж—¶пјҢеҸӘжңүдё»зәҝзЁӢзҡ„иҝҗиЎҢзәҝзЁӢеӯҳеңЁпјҢеңЁжү§иЎҢзҡ„иҝҮзЁӢдёӯпјҢиӢҘйҒҮеҲ°OpenMP зҡ„жҢҮд»ӨиҰҒжұӮ并иЎҢжү§иЎҢж—¶пјҢдё»зәҝзЁӢдјҡжҙҫз”ҹеҮәеӯҗзәҝзЁӢжқҘжү§иЎҢ并иЎҢд»»еҠЎгҖӮеңЁе№¶иЎҢжү§иЎҢзҡ„иҝҮзЁӢдёӯпјҢз”ұдё»зәҝзЁӢдёҺжҙҫз”ҹеҮәзҡ„еӯҗзәҝзЁӢз»„жҲҗдёҖдёӘзәҝзЁӢз»„жқҘеҚҸеҗҢе·ҘдҪңгҖӮеңЁе№¶иЎҢжү§иЎҢз»“жқҹеҗҺпјҢжҙҫз”ҹеҮәзҡ„еӯҗзәҝзЁӢйҖҖеҮәжҲ–жҢӮиө·пјҢдёҚеҶҚе·ҘдҪңпјҢжҺ§еҲ¶жөҒзЁӢеӣһеҲ°еҚ•зӢ¬зҡ„дё»зәҝзЁӢдёӯпјҢзӣҙеҲ°дёӢдёҖдёӘ并иЎҢеҢәжҲ–иҖ…зЁӢеәҸжү§иЎҢе®ҢжҜ•гҖӮ
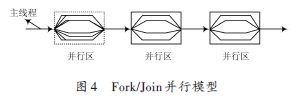
2.3 FDTDз®—жі•зҡ„并иЎҢеҢ–
еңЁз”ЁFDTDз®—жі•жЁЎжӢҹи®Ўз®—з”өзЈҒеңәзҡ„иҝҮзЁӢдёӯпјҢж—¶й—ҙжӯҘй•ҝдёҠзҡ„иҝӯд»ЈиҝҮзЁӢжҳҜзӣёе…іиҒ”зҡ„гҖҒдә’зӣёеҪұе“Қзҡ„пјҢж•…иҖҢдёҚиғҪе®һзҺ°е№¶иЎҢеҢ–гҖӮдҪҶжҳҜеңЁдёҖж¬Ўиҝӯд»ЈеҶ…йғЁпјҢз”өеңәдёҺзЈҒеңәзҡ„и®Ўз®—д»…йңҖиҰҒеүҚдёҖж—¶еҲ»зҡ„и®Ўз®—з»“жһңпјҢдёҺе…¶д»–еҢәеҹҹзҡ„з”өеңәжҲ–иҖ…зЈҒеңәеҲҶйҮҸж— е…іпјҢеҗ„дёӘи®Ўз®—иҝҮзЁӢд№Ӣй—ҙжІЎжңүеҪұе“ҚгҖҒзӣёдә’зӢ¬з«ӢпјҢеҸҜд»Ҙе®һзҺ°е№¶иЎҢеҢ–гҖӮдёәжӯӨпјҢжң¬ж–ҮйҮҮз”ЁOpenMPжҸҗдҫӣзҡ„з»ҶзІ’еәҰ并иЎҢзҡ„ж–№ејҸеҜ№иҜҘз®—жі•е®һзҺ°е№¶иЎҢеҢ–пјҢеҚіOpenMP+з»ҶзІ’еәҰ并иЎҢгҖӮ
3гҖҒ并иЎҢFDTD жҖ§иғҪеҲҶжһҗ
3.1 д»ҝзңҹз®—дҫӢи®ҫи®Ў
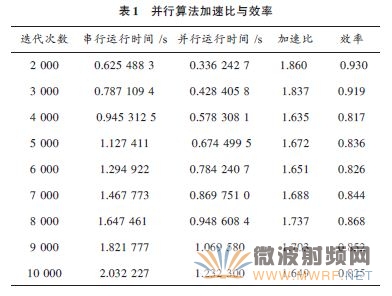
дёәйӘҢиҜҒFDTD算法并иЎҢзҡ„жҖ§иғҪпјҢд»Ҙз”өзЈҒжіўеңЁиҮӘз”ұз©әй—ҙдёӯдј ж’ӯзҡ„дёҖз»ҙFDTD з®—жі•дёәдҫӢпјҢйҮҮз”ЁOpenMP жҸҗдҫӣзҡ„з»ҶзІ’еәҰжҠҖжңҜе®һзҺ°е№¶иЎҢеҢ–гҖӮжҝҖеҠұжәҗйҮҮз”ЁGaussи„үеҶІжәҗпјҢе…¶еёҰе®Ҫдёә10 GHz,τ = 0.2 ns, t0 = 0.8 - τ = 0.16 ns,жҖ»еңәиҫ№з•Ңдёәz0 = 500Δz еӨ„пјҢΔt = τ/ 80 = 0.002 5 ns, Δt = dz/ (2c)пјҢеҗёж”¶иҫ№з•ҢйҮҮз”ЁдёҖйҳ¶иҝ‘дјјMur,жіўдј ж’ӯзҡ„з©әй—ҙеҢәеҹҹдёәиҠӮзӮ№1~1 000.з”Ёз»ҹи®Ўзҡ„ж–№жі•пјҢеҲҶеҲ«жөӢйҮҸдәҶ2 000~10 000 д№Ӣй—ҙдёҚеҗҢиҝӯд»Јж¬Ўж•°зҡ„串并иЎҢж—¶й—ҙгҖӮ
3.2 并иЎҢжҖ§иғҪжөӢиҜ•
并иЎҢзЁӢеәҸжҖ§иғҪжөӢиҜ•еҸҜз”ұ并иЎҢз®—жі•зҡ„еҠ йҖҹжҜ”е’Ң并иЎҢж•ҲзҺҮжқҘиЎЎйҮҸпјҢеҒҮи®ҫжңүn дёӘ并иЎҢйғЁд»¶пјҢеҲҷеҜ№еҠ йҖҹжҜ”гҖҒж•ҲзҺҮзҡ„е®ҡд№үеҰӮдёӢпјҡ
(1)еҠ йҖҹжҜ”speedup=еҚ•дёҖи®Ўз®—жңәиҝҗиЎҢж•ҙдёӘзЁӢеәҸжүҖиҠұиҙ№ж—¶й—ҙеҗҢдёҖеҸ°и®Ўз®—жңәдҪҝз”Ёn дёӘ并иЎҢйғЁд»¶зҡ„жү§иЎҢж—¶й—ҙ;
(2)ж•ҲзҺҮefficiency= speedup n.
зЁӢеәҸ串并иЎҢзҡ„иҝҗиЎҢж—¶й—ҙз”ұOpenMP еә“еҮҪж•°жҸҗдҫӣзҡ„OMP_get_wtime()еҮҪж•°жқҘжөӢйҮҸгҖӮе…·дҪ“ең°пјҢеңЁжөӢйҮҸдёІиЎҢзЁӢеәҸиҝҗиЎҢж—¶й—ҙж—¶пјҢжіЁйҮҠжҺүдәҶзЁӢеәҸдёӯзҡ„并иЎҢзј–иҜ‘жҢҮеҜјиҜӯеҸҘпјҢ并дҝқжҢҒж—¶й—ҙеҮҪж•°зҡ„дҪҚзҪ®дёҚеҸҳгҖӮжң¬ж–ҮйҮҮз”ЁеӨҡж¬ЎиҝҗиЎҢзЁӢеәҸеҸ–зЁіе®ҡеҖјзҡ„ж–№жі•пјҢеҲҶеҲ«жөӢйҮҸ并记еҪ•дәҶдёҚеҗҢиҝӯд»Јж¬Ўж•°дёӢзҡ„зЁӢеәҸ串并иЎҢиҝҗиЎҢж—¶й—ҙгҖӮ
3.3 жөӢиҜ•зҺҜеўғ
жөӢиҜ•зҺҜеўғдёәIntel(R) Core(TM) 2 Duo CPUT5670@1.8 GHz,еҶ…еӯҳдёә2 GB,ж“ҚдҪңзі»з»ҹдёәWinXP SP3,ејҖеҸ‘иҪҜ件дёәIntel Fortran 10.1.014 with vs 2005,жөӢиҜ•з»“жһңеҰӮиЎЁ1жүҖзӨәгҖӮ
3.4 并иЎҢж–№жі•йӘҢиҜҒ
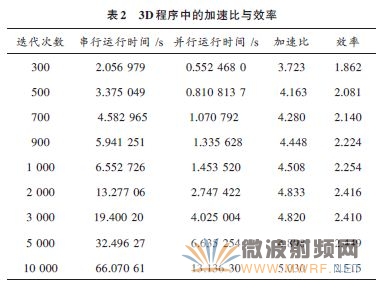
дёәдәҶйӘҢиҜҒжң¬ж–ҮжүҖйҮҮз”Ёзҡ„OpenMP 并иЎҢз®—жі•зҡ„еҸҜиЎҢжҖ§пјҢе°ҶиҜҘ并иЎҢж–№жі•еә”з”ЁдәҺдёүз»ҙзһ¬жҖҒеңәз”өеҒ¶жһҒеӯҗиҫҗе°„FDTDзЁӢеәҸдёӯгҖӮи®ҫж•ҙдёӘи®Ўз®—еҹҹз©әй—ҙдёәзңҹз©әпјҢеһӮзӣҙзӮ№еҒ¶жһҒеӯҗдҪҚдәҺи®Ўз®—еҹҹдёӯеҝғпјҢеҚіEz(0,0,0)пјҢFDTDи®Ўз®—з©әй—ҙжӯҘй•ҝдёә5 cm,ж—¶й—ҙжӯҘй•ҝдёә83.333 ps,и®Ўз®—еҹҹдёә55×55×55 дёӘе…ғиғһпјҢжҲӘж–ӯиҫ№з•ҢдёәMurеҗёж”¶иҫ№з•ҢпјҢиҫҗе°„жәҗдёәй«ҳж–Ҝи„үеҶІпјҢжөӢйҮҸ并记еҪ•дәҶ300~10 000д№Ӣй—ҙдёҚеҗҢиҝӯд»Јж¬Ўж•°зҡ„串并иЎҢж—¶й—ҙпјҢжөӢйҮҸз»“жһңи§ҒиЎЁ2.
4гҖҒз»“и®ә
жң¬ж–Үд»ҺеҲҶжһҗOpenMPжң¬иә«зҡ„зү№зӮ№еҸҠзј–зЁӢжЁЎеһӢе…ҘжүӢпјҢз»“еҗҲдёҖз»ҙFDTDз®—жі•е®һдҫӢпјҢйҮҮз”ЁOpenMP+з»ҶзІ’еәҰ并иЎҢзҡ„ж–№ејҸе®һзҺ°дәҶ并иЎҢеҢ–пјҢ并иҜҒжҳҺдәҶеҹәдәҺOpenMP зҡ„并иЎҢFDTD з®—жі•зҡ„жңүж•ҲжҖ§пјҢиҖҢ且并иЎҢFDTD з®—жі•еңЁжүҖйҖүжөӢиҜ•е®һдҫӢзҡ„дёҚеҗҢиҝӯд»Јж¬Ўж•°дёҠеқҮиҺ·еҫ—дәҶи¶…зәҝжҖ§зҡ„еҠ йҖҹжҜ”гҖӮе……еҲҶеҲ©з”ЁдәҶOpenMPе…ұдә«еӯҳеӮЁдҪ“зі»з»“жһ„зҡ„зү№зӮ№пјҢйҒҝе…ҚдәҶж¶ҲжҒҜдј йҖ’еёҰжқҘзҡ„ејҖй”ҖпјҢеҸ–еҫ—дәҶиҫғ其他并иЎҢFDTDз®—жі•жӣҙеҝ«еҠ йҖҹжҜ”е’Ңжӣҙй«ҳзҡ„ж•ҲзҺҮгҖӮжӣҙеҖјеҫ—дёҖжҸҗзҡ„жҳҜпјҢе°ҶиҜҘ并иЎҢж–№жі•еә”з”ЁеңЁдёүз»ҙз”өзЈҒеңәFDTD зЁӢеәҸдёӯд№ҹеҸ–еҫ—дәҶеҫҲеҘҪзҡ„еҠ йҖҹжҜ”е’Ңж•ҲзҺҮпјҢеҸҜд»Ҙйў„и§ҒпјҢиҜҘдјҳеҢ–ж–№жі•еңЁжӣҙеӨҚжқӮзҡ„з®—жі•дёӯеә”з”ЁдёҖе®ҡе…·жңүжӣҙзҗҶжғізҡ„жҖ§иғҪжҸҗеҚҮгҖӮдҪҶдёҚи¶ід№ӢеӨ„еңЁдәҺзі»з»ҹзҡ„еҸҜжү©еұ•жҖ§е·®пјҢиҝҷжҳҜз”ұдәҺOpenMP жң¬иә«зҡ„зү№зӮ№жүҖйҷҗеҲ¶гҖӮ
еӣ жӯӨпјҢд»ҠеҗҺзҡ„е·ҘдҪңе°Ҷж”ҫеңЁеҜ№еҹәдәҺSMP жңәзҫӨзҡ„MPI дёҺOpenMPж··еҗҲзј–зЁӢжЁЎеһӢзҡ„з ”з©¶пјҢд»ҺиҖҢе…ӢжңҚзі»з»ҹжү©еұ•жҖ§е·®зҡ„зјәзӮ№пјҢиҝӣиҖҢжҸҗеҚҮзі»з»ҹзҡ„жҳ“з”ЁжҖ§е’ҢеҸҜ移жӨҚжҖ§гҖӮ
 зІӨе…¬зҪ‘е®үеӨҮ 44030902003195еҸ·
зІӨе…¬зҪ‘е®үеӨҮ 44030902003195еҸ·